苹果剑桥强强联合:AI 评审框架突破复杂任务评审难题

AI ToolBox
2025年7月24日
突破传统评审局限,AI评估系统迎来新升级
据科技媒体 NeoWin 报道,苹果公司与剑桥大学近日联合提出一种全新的 AI 评估系统,旨在通过引入外部验证工具,增强 AI 评审员的能力,从而显著提升评估结果的准确性与可靠性。
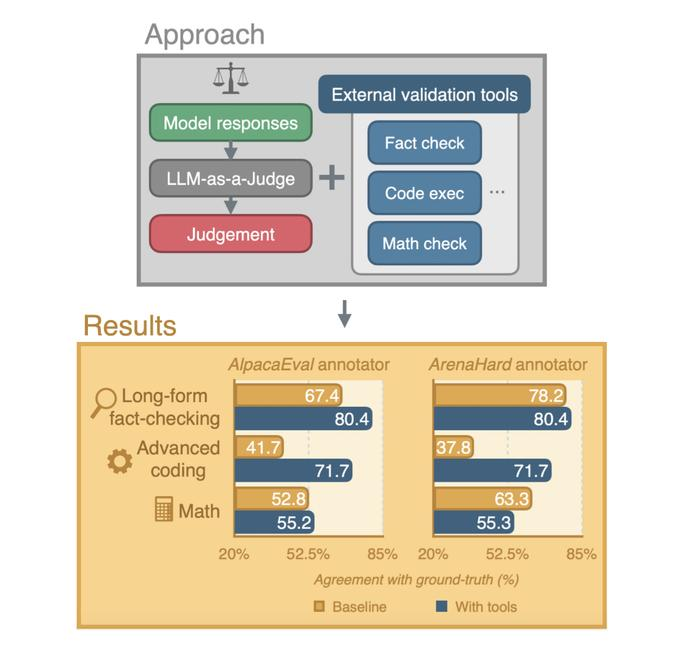
LLM-as-a-Judge 模式面临挑战
当前,研究人员和开发者越来越多地采用"LLM-as-a-Judge"方式评估大语言模型(LLM),即利用 AI 对其他 AI 的输出进行评审。然而,该方法在面对长文本事实核查、高级编程任务和数学推理等复杂场景时,往往存在评估质量下降的问题。
构建自主评估代理,提升判断能力
为解决上述问题,研究团队设计了一种具备自主判断能力的评估代理。该系统能根据任务需求,决定是否调用外部验证工具,并选择最合适的工具进行辅助评估。整个流程包括三个关键阶段:初步领域判断 、工具调用 和 最终决策。
三大验证工具协同工作,覆盖多类任务
为应对不同类型任务,研究人员整合了以下三类外部验证工具:
- 事实核查工具:借助网络搜索验证响应中的基本事实。
- 代码执行工具:使用 OpenAI 的代码解释器运行并验证代码输出。
- 数学验证工具:专为数学与算术问题设计的代码执行变体。
智能切换机制,兼顾效率与准确性
当系统判断外部工具无法提供有效辅助时,将自动切换至基线 LLM 注释器,从而避免在简单任务中引入不必要的处理开销,并防止性能下降。