多模态新突破!快手联合上交大发布 Orthus 模型,生成能力飞跃

AI ToolBox
2025年7月24日
全新多模态模型Orthus亮相ICML
在刚刚落幕的国际机器学习大会(ICML)上,快手 与上海交通大学 联合发布了一款备受瞩目的多模态生成理解模型------Orthus。该模型基于自回归 Transformer 架构,实现了图文之间的自由转换,展现出卓越的生成能力,目前已面向公众开源。
高效计算与强大性能兼具
Orthus 最显著的优势在于其出色的计算效率 与强大的学习能力。研究显示,在仅需少量计算资源的条件下,Orthus 在多个图像理解指标上超越了现有主流模型,包括 Chameleon 和 Show-o。更令人印象深刻的是,在文生图任务的 GenEval 指标上,Orthus 表现优于专为此优化的扩散模型 SDXL。
灵活架构赋能多种应用场景
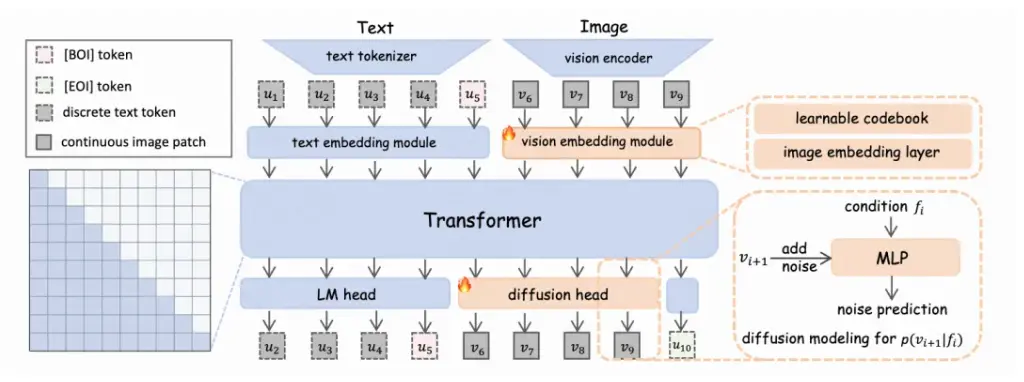
该模型不仅能够高效处理文本与图像之间的交互关系,还在图像编辑、网页生成等实际应用中展现了巨大潜力。其架构设计采用了以自回归 Transformer 为主干网络,并配备专门的模态生成头,分别用于文本和图像生成。这种结构有效解耦了图像细节与文本特征的建模过程,使 Orthus 能更专注于挖掘模态之间的深层关系。
核心组件与统一表示空间
Orthus 由多个关键模块组成,包括文本分词器、视觉自编码器以及两个面向不同模态的嵌入层。通过将文本与图像特征映射到一个统一的表示空间,主干网络能够更高效地处理跨模态依赖。在推理阶段,模型会根据当前标记,自回归地生成下一个文本 token 或图像特征,展现出极高的灵活性。
创新突破与未来展望
借助这些创新设计,Orthus 成功弥合了端到端扩散建模与自回归机制之间的差距,同时降低了图像离散化带来的信息损失。这一成果可被视为何恺明团队在图像生成领域 MAR 工作向多模态方向的重要延伸。
快手与上海交通大学的此次合作,为多模态生成模型的发展开辟了新路径,值得学术界与工业界共同关注与期待。