700 步 RL 炼金术!字节跳动 POLARIS 让 4B 小模型数学吊打 Claude-4-Opus

AI ToolBox
2025年7月16日
创新训练方法提升小模型推理能力
字节跳动Seed团队联合香港大学与复旦大学推出全新强化学习训练方法------POLARIS。该方法通过精心设计的Scaling RL策略,显著增强了小模型在数学推理方面的表现。
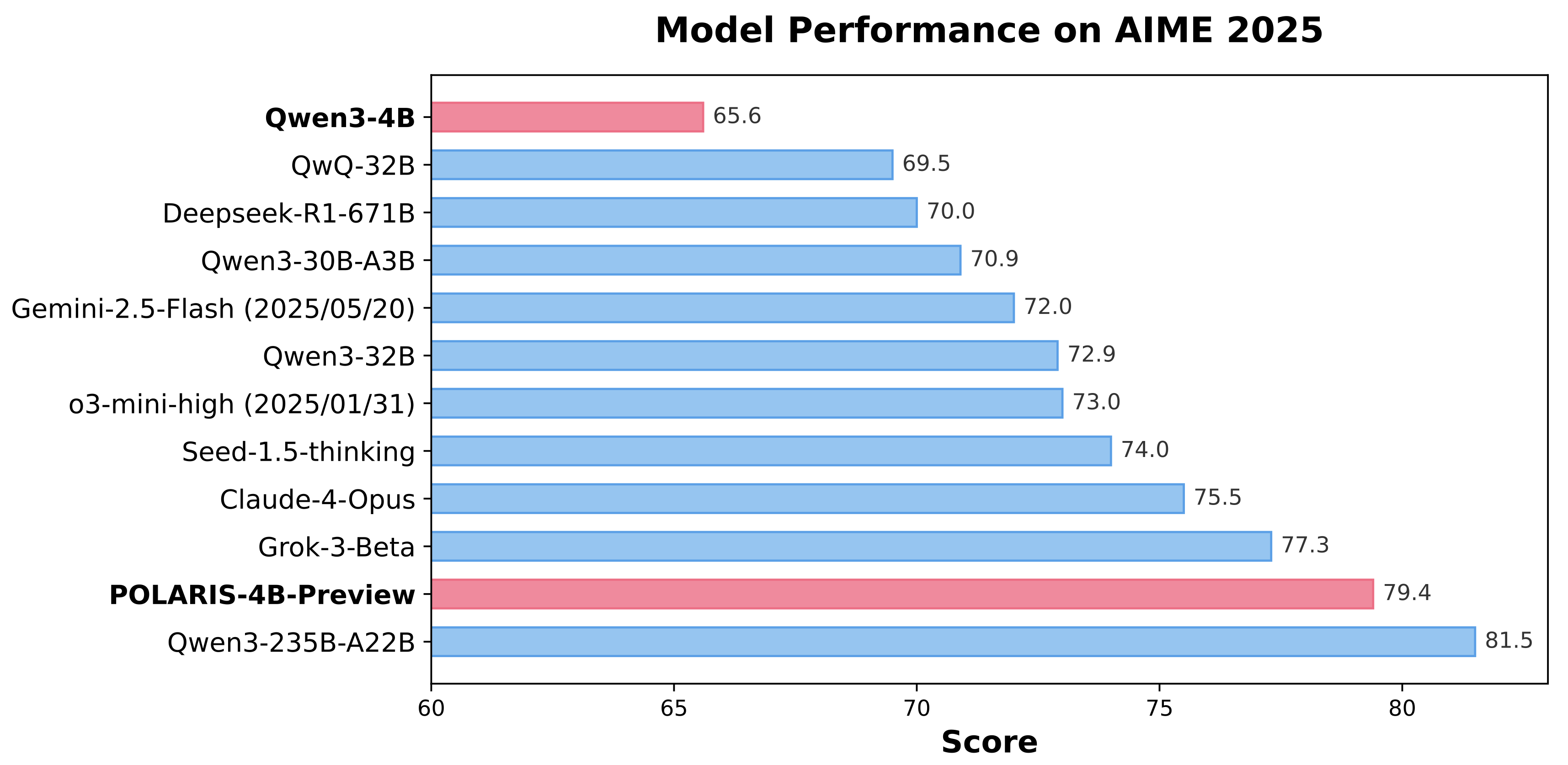
实验数据显示,在AIME25和AIME24测试中,采用POLARIS训练的Qwen3-4B模型分别取得了79.4% 和**81.2%**的准确率,表现出色,甚至优于部分闭源的大规模模型。
轻量化设计实现高效部署
POLARIS-4B模型具备良好的轻量化特性,能够在消费级显卡上顺利运行,极大降低了实际应用门槛。
核心训练策略解析
研究团队围绕待训练模型定制了训练数据和超参数配置,以有效增强其推理能力:
- 动态调整训练数据难度分布,构建略微偏向难题的数据集,避免样本难度过于集中;
- 引入数据动态更新机制,根据模型表现实时剔除简单样本,确保训练有效性。
采样控制优化多样性
POLARIS通过精确控制采样温度,在模型性能与生成路径多样性之间实现了良好平衡:
- 过高的采样温度可能引发不稳定输出,而过低则限制多样性;
- 团队提出"探索区"温度初始化方案,并在训练过程中动态调整,维持内容生成质量。
应对长上下文挑战
为解决长文本处理难题,POLARIS引入长度外推技术:
- 通过对位置编码RoPE进行调整,使模型能处理超出训练时所见长度的序列;
- 这一改进显著提升了模型在长文本任务中的适应能力和表现。
多阶段RL训练策略
POLARIS采用渐进式训练方式:
- 初期使用较短的上下文窗口进行训练;
- 待模型表现趋于稳定后逐步增加窗口长度;
- 有助于模型逐步适应复杂推理任务,提高训练稳定性与最终效果。
开源成果与广泛应用验证
目前,POLARIS的完整训练方法、数据集、代码及实验模型均已公开发布。
研究团队在多个主流推理评测集上进行了验证,结果显示,无论是不同规模还是不同架构的模型,在采用POLARIS训练后均有明显提升。
项目地址
Github 主页:https://github.com/ChenxinAn-fdu/POLARIS
Hugging Face 主页:https://huggingface.co/POLARIS-Project