循环模型再升级:500步训练攻克超长序列难题

AI ToolBox
2025年7月8日
循环模型崛起:挑战Transformer霸主地位
在深度学习领域,RNN 与 Transformer 曾各领风骚。如今,线性循环模型(如 Mamba)凭借卓越的序列处理能力,正逐步改变格局。
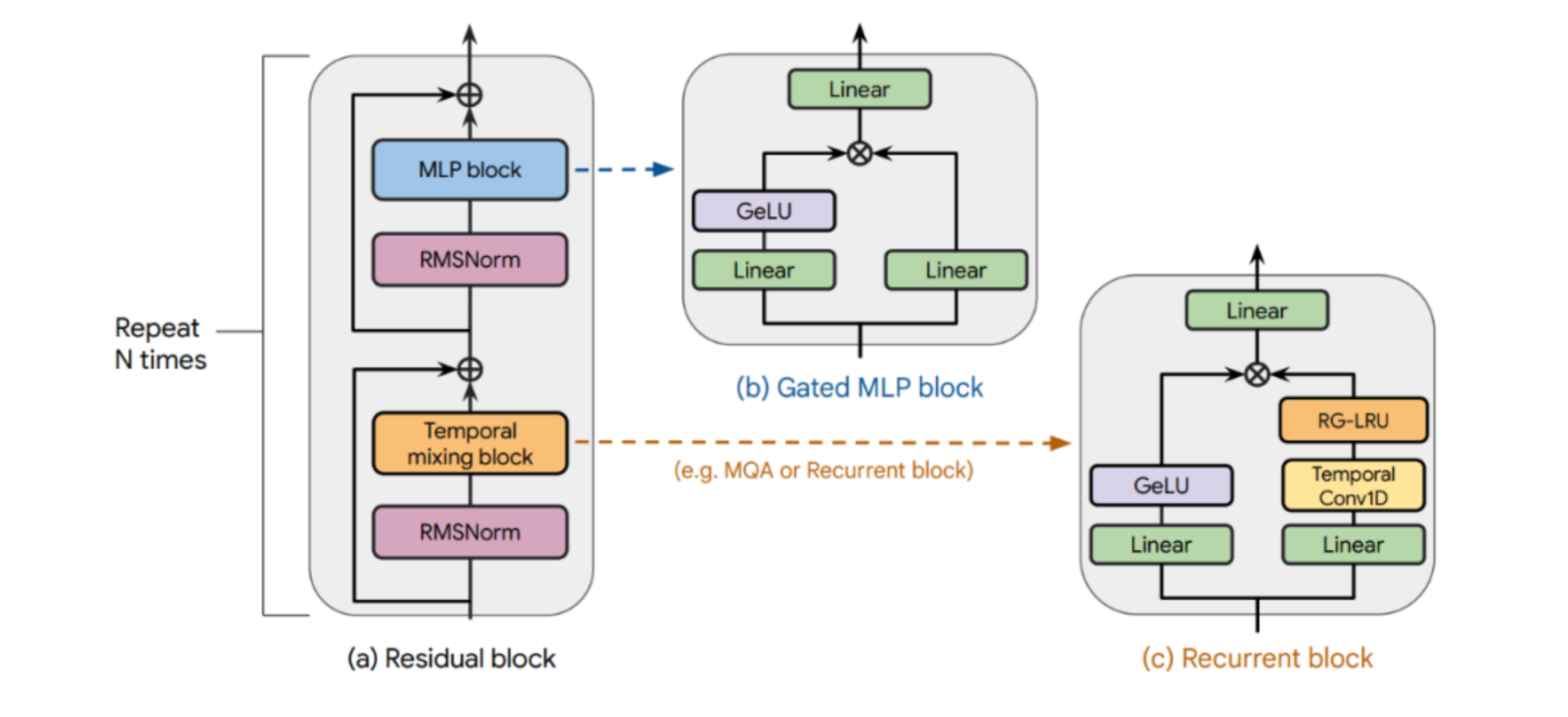
特别是在极长序列任务中,这些新型循环模型展现出惊人的潜力,远超传统 Transformer 的性能瓶颈。
Transformer 的局限性
Transformer 在处理长上下文时面临两大难题:一是固定上下文窗口限制,二是计算复杂度随序列长度迅速上升,导致整体性能下降。
反观线性循环模型,它们能够更灵活高效地应对长序列任务,这是其显著优势所在。
循环模型短板被打破
过去,循环模型在短序列任务中的表现往往不如 Transformer,这限制了其广泛应用。
然而,卡内基梅隆大学与 Cartesia AI 的最新研究彻底改变了这一认知。他们通过仅需 500 步的训练干预,使循环模型轻松处理长达 256k 的序列,展现出前所未有的泛化能力。
研究明确指出:循环模型并非存在结构性缺陷,而是潜能尚未被充分激发。
创新理论与训练方法
研究团队提出全新解释框架 ------ "未探索状态假说"。该假说认为,训练过程中模型接触的状态分布有限,是其在长序列上表现不佳的根本原因。
为实现长度泛化,他们引入多项训练干预策略,包括:
- 引入随机噪声
- 使用拟合噪声
- 采用状态传递机制
这些方法显著提升了模型在长序列任务中的适应力和稳定性。
实际验证与未来方向
实验结果表明,经过优化后的循环模型在各类长上下文任务中表现优异,不仅性能提升,系统稳定性也得到有效保障。
这项研究为循环模型的发展打开了新的思路,也为构建更高效的序列建模方案提供了坚实基础。