DLoRAL技术开源,香港理工大学与OPPO联手推动视频超分辨率领域发展

AI ToolBox
2025年7月8日
创新双LoRA架构,兼顾时间与空间
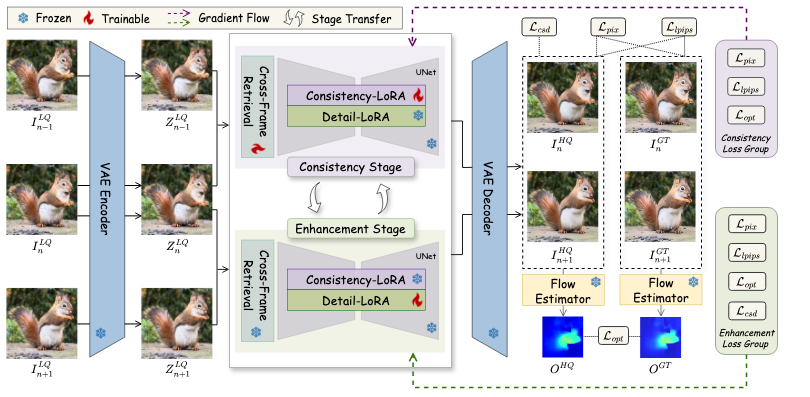
DLoRAL(Dual LoRA Learning)基于预训练扩散模型Stable Diffusion V2.1构建,采用独特的双LoRA架构,在视频超分辨率领域实现重大突破。该框架由两个定制化的LoRA模块组成:
- CLoRA :专注于视频帧之间的时间一致性。通过提取输入视频中的时序特征,确保各帧之间过渡自然,有效消除传统方法中常见的闪烁或跳跃现象。
- DLoRA :致力于提升画面的空间细节表现。通过对高频信息的优化处理,显著增强画面清晰度和质感,让低清视频呈现高清视觉效果。
这种架构将时间连贯性与空间细节解耦处理,借助轻量模块嵌入现有模型,既降低了计算开销,又提升了输出质量。
双阶段训练策略,效率与质量双赢
DLoRAL采用两阶段交替训练机制,分别聚焦于一致性与细节增强,从而达到最优效果:
- 一致性阶段:利用CLoRA与CrossFrame Retrieval(CFR)模块,并结合时序一致性损失函数,优化动态场景下的帧间连贯性,确保输出视频流畅自然。
- 增强阶段:在冻结CLoRA与CFR的基础上,专注训练DLoRA模块,融合分类器分数蒸馏(CSD)等技术,进一步强化画面锐度与纹理细节。
这一策略使DLoRAL在推理阶段可通过单步生成,将两个LoRA模块无缝集成至冻结的扩散UNet中,实现高效、高质量的视频输出。相比传统多步迭代方法,推理速度提升约10倍,展现出卓越的效率优势。
开源赋能,助力学术与产业
DLoRAL作为开源项目发布,为科研人员与企业开发者提供了宝贵资源。代码、训练数据及预训练模型已于2025年6月24日公开于GitHub,项目页面还附有简明讲解视频与丰富视觉示例。
在多项评估指标如PSNR与LPIPS上,DLoRAL均表现出色,超越当前主流RealVSR方法。然而,受限于Stable Diffusion所使用的8倍下采样变分自编码器(VAE),其在极小文本等细微结构的恢复方面仍存在改进空间。
视频超分辨率的未来风向
DLoRAL的诞生标志着视频超分辨率技术迈入一个全新阶段。凭借其高效的单步生成能力与完全开源特性,该框架大幅降低了视频高清化的技术门槛。
随着更多研究者与企业在DLoRAL基础上进行拓展开发,视频处理领域有望迎来诸多创新应用,例如实时视频增强 、影视后期优化等,推动整个行业迈向更高水平。