Grok 4 基准测试成绩泄露:惊人表现引热议与质疑

AI ToolBox
2025年7月5日
AI资讯
全新AI模型Grok 4测试成绩泄露,社区反响强烈
近日,X平台博主 @legit_api 晒出 Grok 4 的基准测试结果,在AI圈内掀起轩然大波。此次披露不仅包括通用旗舰模型 Grok 4,还有专攻编程的 Grok 4 Code。
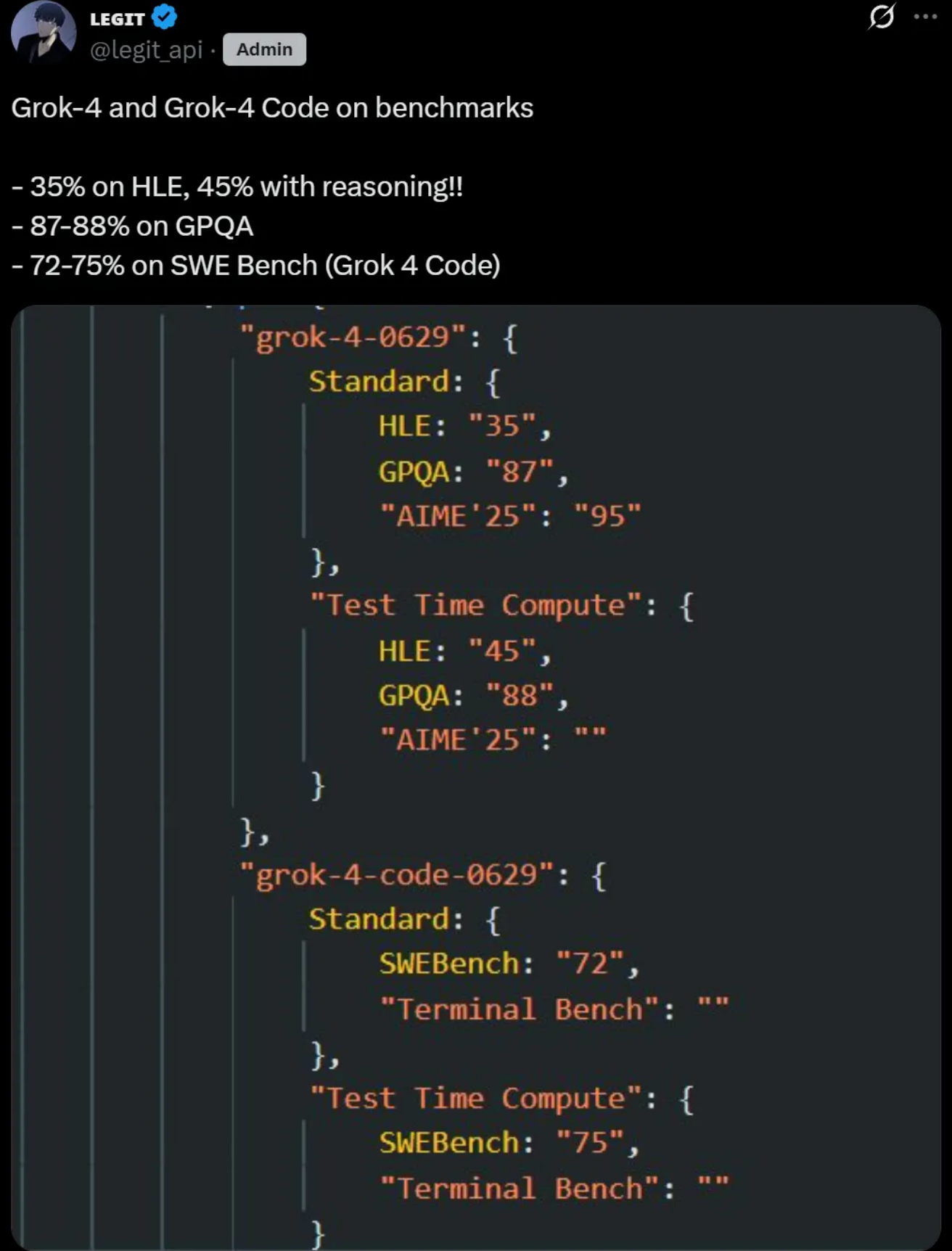
性能方面令人瞩目:
- 在 HLE 自由回答测试中,标准模式下得分为 35%,通过推理技术加持后飙升至 45%,远胜 Gemini 2.5 Pro、OpenAI o3 及 GPT-4o;
- GPQA 测试得分稳定在 87 - 88%,与 OpenAI o3 并列顶尖水平;
- AIME '25 测试更是取得 95% 的优异成绩。
Grok 4 Code 在 SWE Bench 编程任务中表现同样亮眼,得分范围为 72 - 75%,与 Claude Opus 4 齐平,略优于 OpenAI o3。
高分引质疑,真实性成焦点
尽管成绩斐然,争议也随之而来。HLE 测试中 45% 的高分尤其惹眼,不少网友对其评估方法提出疑问。有观点指出 xAI 团队过往存在报告标准不一致的情况,而该测试内容涵盖大量复杂检索项,如此高分难以解释。
@legit_api 虽坚称数据真实,但未能提供具体测试配置信息。除 HLE 成绩外,其他指标则普遍被接受。
Grok 4定位与技术亮点
Grok 4 主打自然语言处理、数学计算与逻辑推理能力,于6月29日完成训练,目前仅支持文本输入,上下文窗口约为13万个 tokens。虽然不及部分竞品宽广,但更注重推理效率。
其编程版本 Grok 4 Code 可无缝集成至编辑器中,实时解决编码难题。开发过程中,马斯克亲临现场,"帐篷办公",通宵达旦推进项目,彰显团队破釜沉舟的决心。
发布临近?社区翘首以盼
截至目前,Grok 4 尚未正式发布,但推特平台上的 Grok 功能已出现更新迹象。结合本次测试数据流出,外界对其发布时间充满期待。
若成绩属实,Grok 4 或将凭借架构革新或规模拓展,引领 AI 大模型新一轮发展浪潮。不过最终结论仍需等待官方确认。