DeepMind 新突破:Crome 引领大型语言模型精准对齐人类反馈

因果驱动:构建更稳健的奖励模型
在人工智能领域,奖励模型是实现大型语言模型(LLMs)与人类反馈对齐的核心组件,但其当前版本常受"奖励黑客"问题困扰。
现有模型往往侧重于回复长度或格式等表面特征,而非关注事实准确性与相关性等真正质量指标。这一缺陷源于标准训练目标无法区分数据中的虚假关联与真实因果关系,从而导致生成脆弱的奖励模型(RMs),进而影响策略对齐效果。
传统方法存在局限
目前的解决方案包括修改模型架构、进行策略级调整以及采用集合或一致性检查的数据中心方法,以缓解 Bradley-Terry 或成对排名系统带来的问题。此外,一些近期的因果启发式方法尝试引入 MMD 正则化来抑制预设的虚假因素,或通过修正重写估计因果效应。
然而,这些方法仅针对已知的虚假变量,难以应对未知的干扰因素。尽管已有增强策略和评估导向方案,但在面对多样化虚假线索时,仍缺乏有效的训练机制。
Crome:基于因果理解的新方法
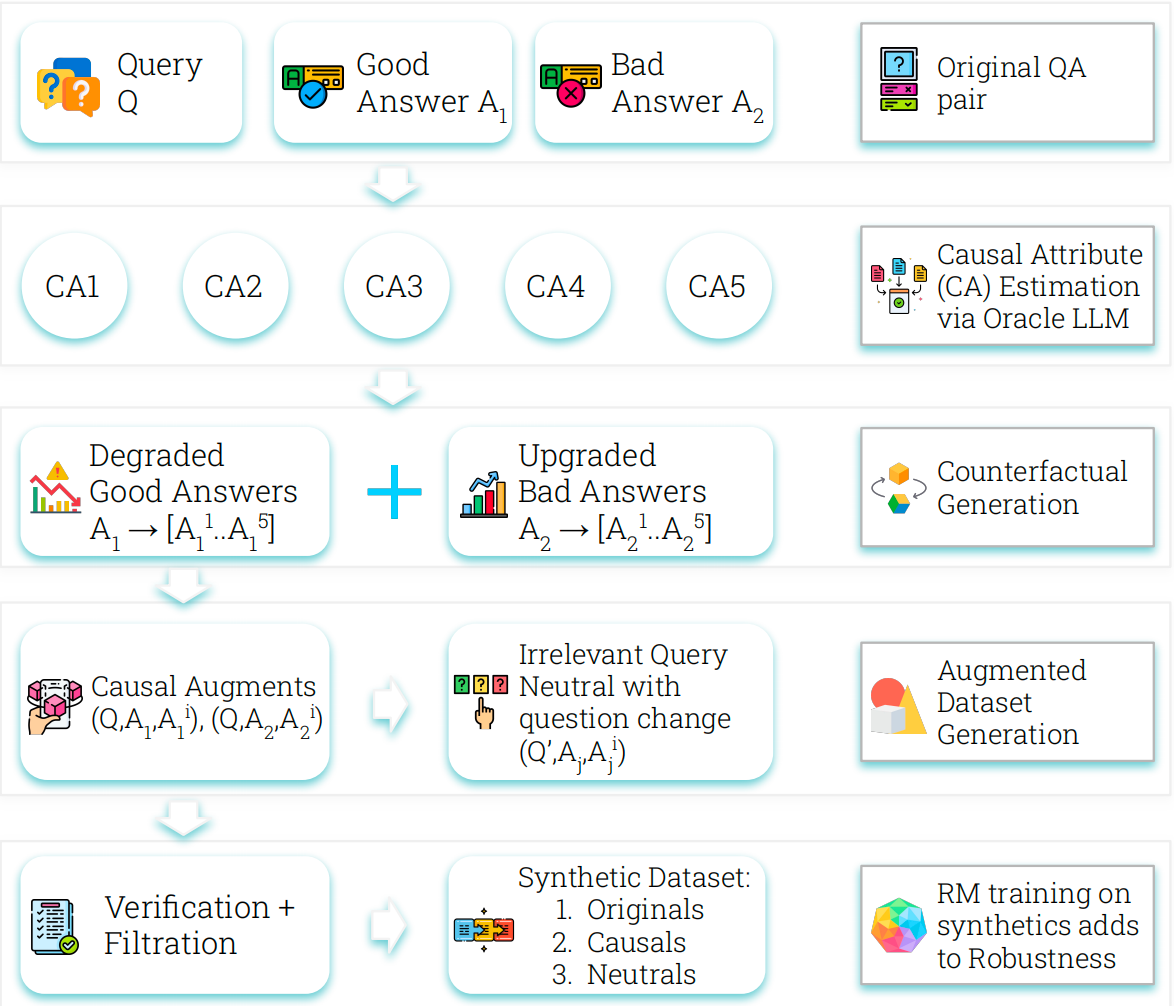
为解决上述挑战,来自谷歌 DeepMind、麦吉尔大学及 MILA - 魁北克人工智能研究所的研究人员提出了 Crome(因果鲁棒奖励建模)框架。
Crome 建立在明确的答案生成因果模型基础上,通过引入由大型语言模型生成的反事实示例来扩充偏好数据集,从而使奖励模型能够有效区分质量本质与表面特征。
- 因果增强:强化模型对核心质量属性的敏感度;
- 中性增强:提升模型对无关变量的不变性。
Crome 的运作分为两个阶段:生成属性感知的反事实数据 和 基于组合数据的损失函数优化训练过程。实验表明,该方法在多个基础 LLM 上均取得显著性能提升,如 Gemma-2-9B-IT 和 Qwen2.5-7B。
性能与安全双重提升
Crome 在多项基准测试中表现优异,尤其在推理能力和内容安全性方面进步明显。它在 WildGuardTest 测试中成功降低了有害提示的攻击成功率,同时维持了对良性提示的正常处理能力。
未来展望
研究人员表示,未来的工作将聚焦于扩展因果数据增强技术,推动高质量合成数据生成,为基础模型的训练开辟新路径。